Stop Prompt Engineering. Start Building Infrastructure.
Stop Prompt Engineering. Start Building Infrastructure.
Last week I opened a terminal, typed six words, and watched PAI spend the next three minutes processing a set of handwritten study notes exported from my reMarkable tablet. It converted the file format, extracted key concepts, generated structured review questions, cross-referenced my existing knowledge base, and saved everything to the correct directories in Obsidian — organized by module, tagged correctly, ready to use. I did not write a prompt. I did not explain what certification I was studying. I did not describe the output structure I wanted. I just named the module.
Eighteen months ago, that same task would have started with a paragraph explaining what the reMarkable export format was, what the certification covered, how I organized notes in Obsidian, what level of detail I wanted in the summary, and what format the quiz questions should follow — and another paragraph if I wanted the output saved to a specific location. Every single session. From scratch.
That gap is the entire argument for building an AI harness instead of staying in a chat window.
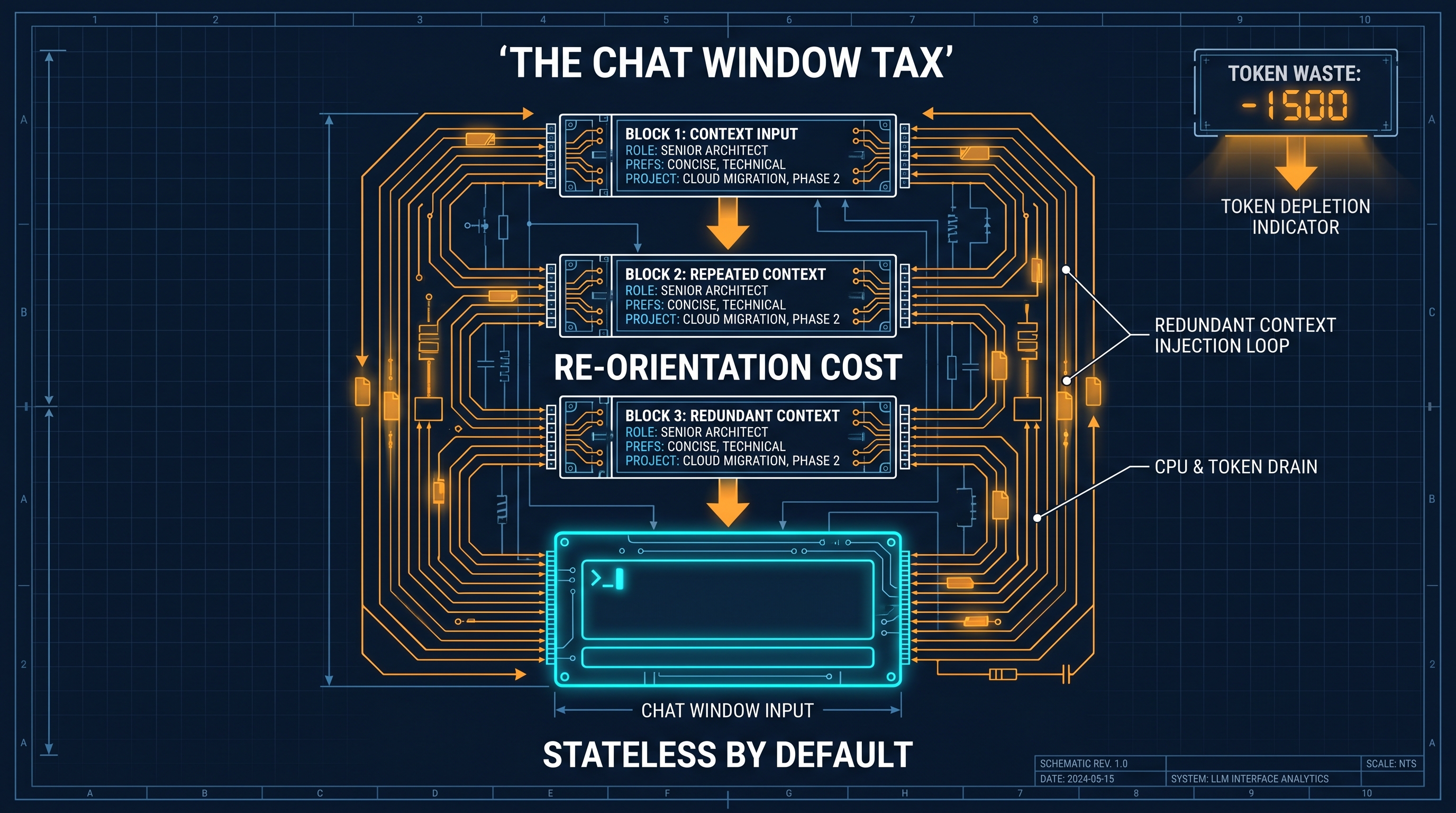
The Chat Window Tax
Prompt engineering emerged as a discipline because LLMs are stateless by default. Every conversation starts with a blank model. If you want the model to know who you are, what you work on, how you like your outputs formatted, and which approach you prefer for recurring problems — you have to tell it. Every time.
That is a tax. Not a feature. A tax.
The people who got good at prompt engineering got skilled at paying that tax efficiently — writing shorter context dumps, using system prompts in API playgrounds, building prompt libraries they paste from. It helped. But it never made the tax go away. It just made each payment slightly cheaper.
In 2026, paying that tax is a choice. The tools exist to stop paying it entirely.
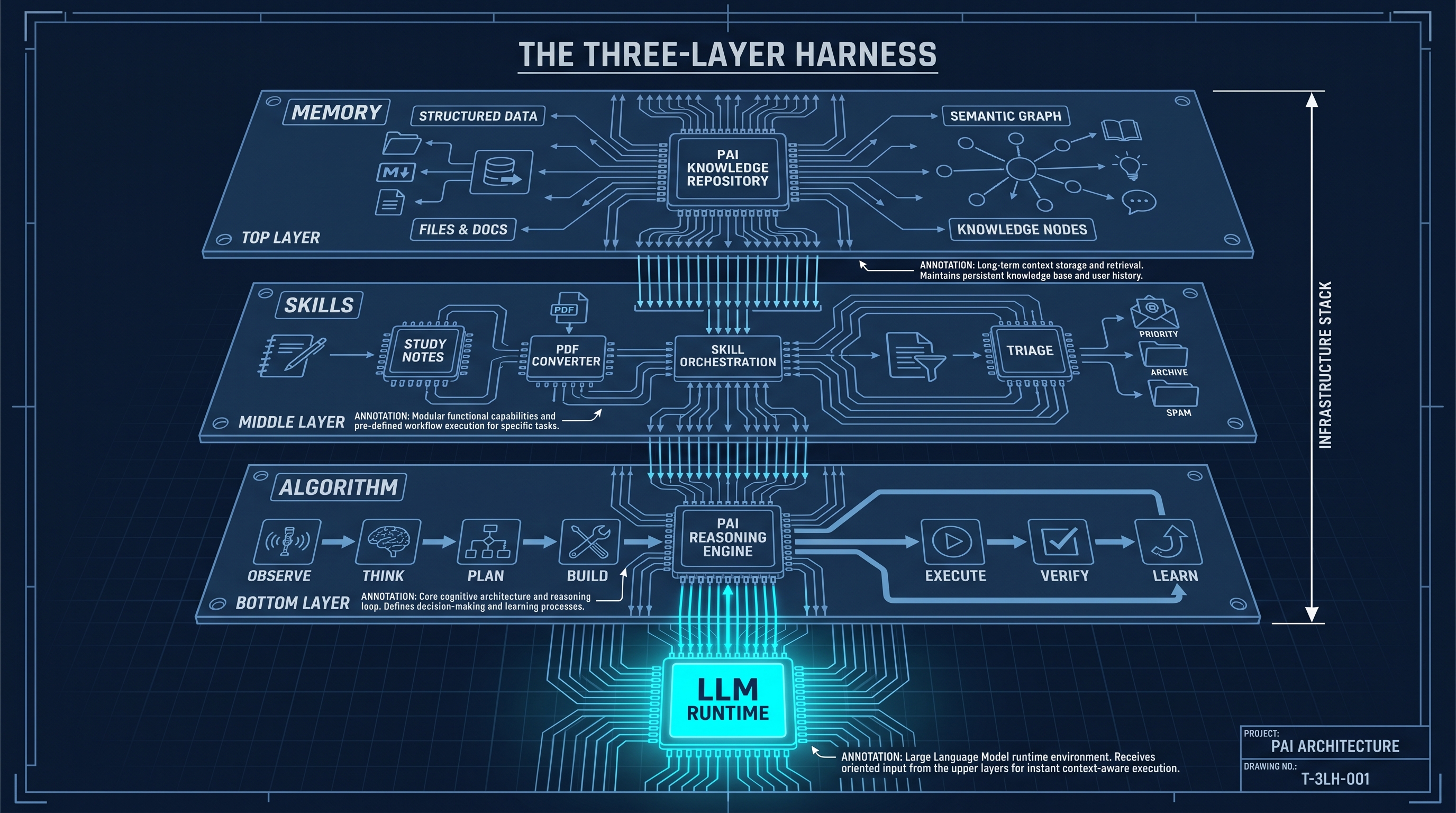
What a Harness Actually Does
A harness is infrastructure wrapped around your AI runtime. In my case, that is PAI — Personal AI Infrastructure — running on top of Claude Code in the terminal. The architecture has three layers.
Memory is persistent context that survives across sessions. PAI knows my role (HRIS analyst), my platform (Oracle HCM Cloud), my Oracle triage methodology, my blog’s writing conventions, my active projects, and my preferences for output formats. None of that gets re-entered. It gets loaded automatically at session start.
Skills are pre-built, parameterized workflows. When I say “process my study notes,” a skill handles that — reading from the right directory, converting the format, saving to the right Obsidian path, cross-referencing the knowledge base. The skill is the prompt, written once, tested, improved over time. I do not craft it fresh every time.
The Algorithm is a structured execution framework. When the work is complex — multi-step, multi-file, non-trivial — PAI runs through a defined process: observe, think, plan, build, execute, verify, learn. The output is consistent because the process is consistent.
Taken together, these three things mean the model is never starting from zero. It arrives at each session already oriented.
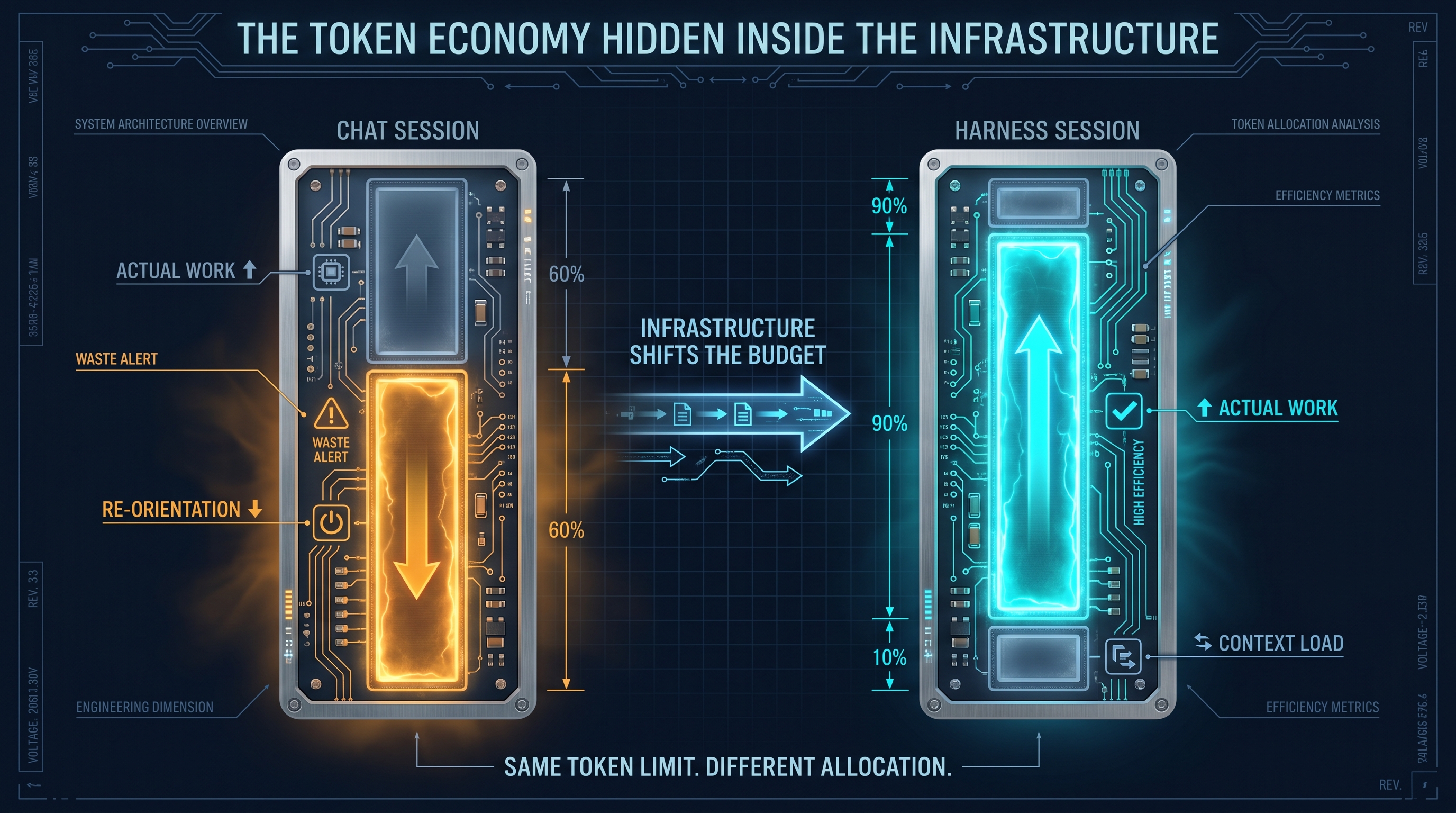
The Token Economy Hidden Inside the Infrastructure
There is a practical angle to this that does not get talked about enough: token consumption.
Every message in a chat session burns tokens — your context, the model’s reasoning, the output, and whatever you paste in to re-establish state. The longer and more complex the session, the faster you burn toward usage limits. When you are re-explaining your role, your project, and your preferences at the start of each conversation, you are spending tokens on re-orientation, not on actual work.
A harness changes the math.
PAI loads persistent context at session start through hooks — but those are structured files read by the runtime, not large prompt blocks the model has to reason through. The model arrives oriented. The working token budget goes toward the task.
More importantly, PAI externalizes logic that would otherwise live inside the conversation. The skills are pre-written workflows. The Algorithm is a structured execution framework. The session hooks handle routing and context injection. A significant portion of what would normally require the model to think its way through — “what directory does this go in?”, “what format does this certification use?”, “what’s the right next step in this process?” — is already answered in scripts and configuration files that run before the model responds.
That is not just more efficient. It changes your usage ceiling. When the model is not spending context budget on re-orientation or derivable decisions, more of each session goes toward meaningful work. You hit limits later, do more per session, and run longer chains of complex tasks without interruption.
Prompt engineering optimizes the prompt. Infrastructure optimizes the budget.
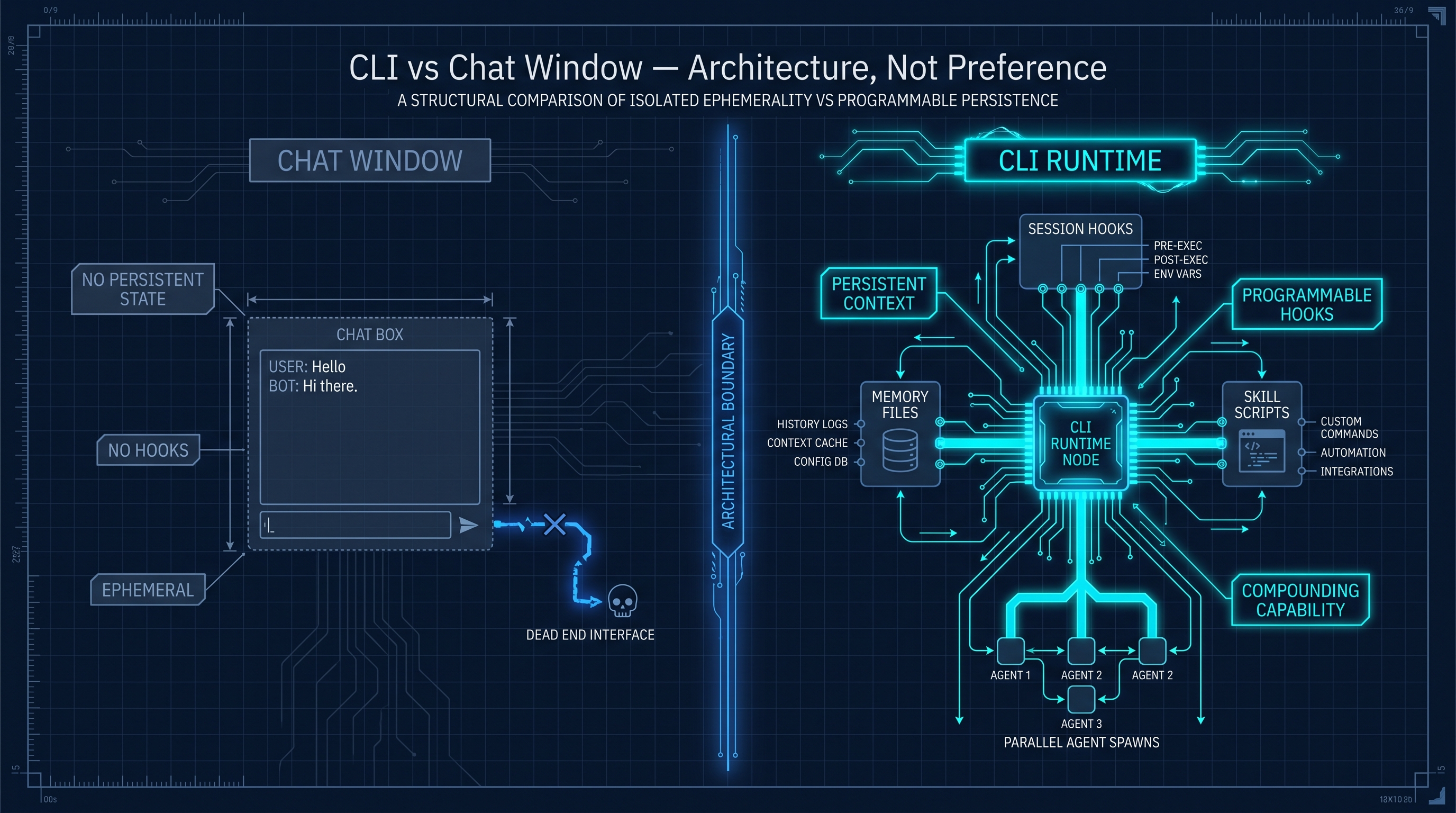
CLI vs. Chat: It Is Architecture, Not Preference
This is the part that took me a while to articulate. The preference for CLI over chat window is not aesthetic — it is structural.
A chat window is a conversation interface. Conversations are ephemeral. They have no persistent state, no programmable hooks, no way to inject context at session start, no way to trigger workflows, no way to store outputs in structured memory. The UX is polished. The architecture is a dead end for anything requiring continuity.
A CLI is a programmable runtime. Session start hooks can load context files. Commands can trigger skills. Outputs can write back to memory. Different agents can be spawned with different contexts and run in parallel. The AI operates inside an environment you built, not inside a box you are renting.
That difference compounds. A chat window is equally capable on day one and day three hundred. A harness gets more capable every time you add a skill, improve the memory, or refine the algorithm.
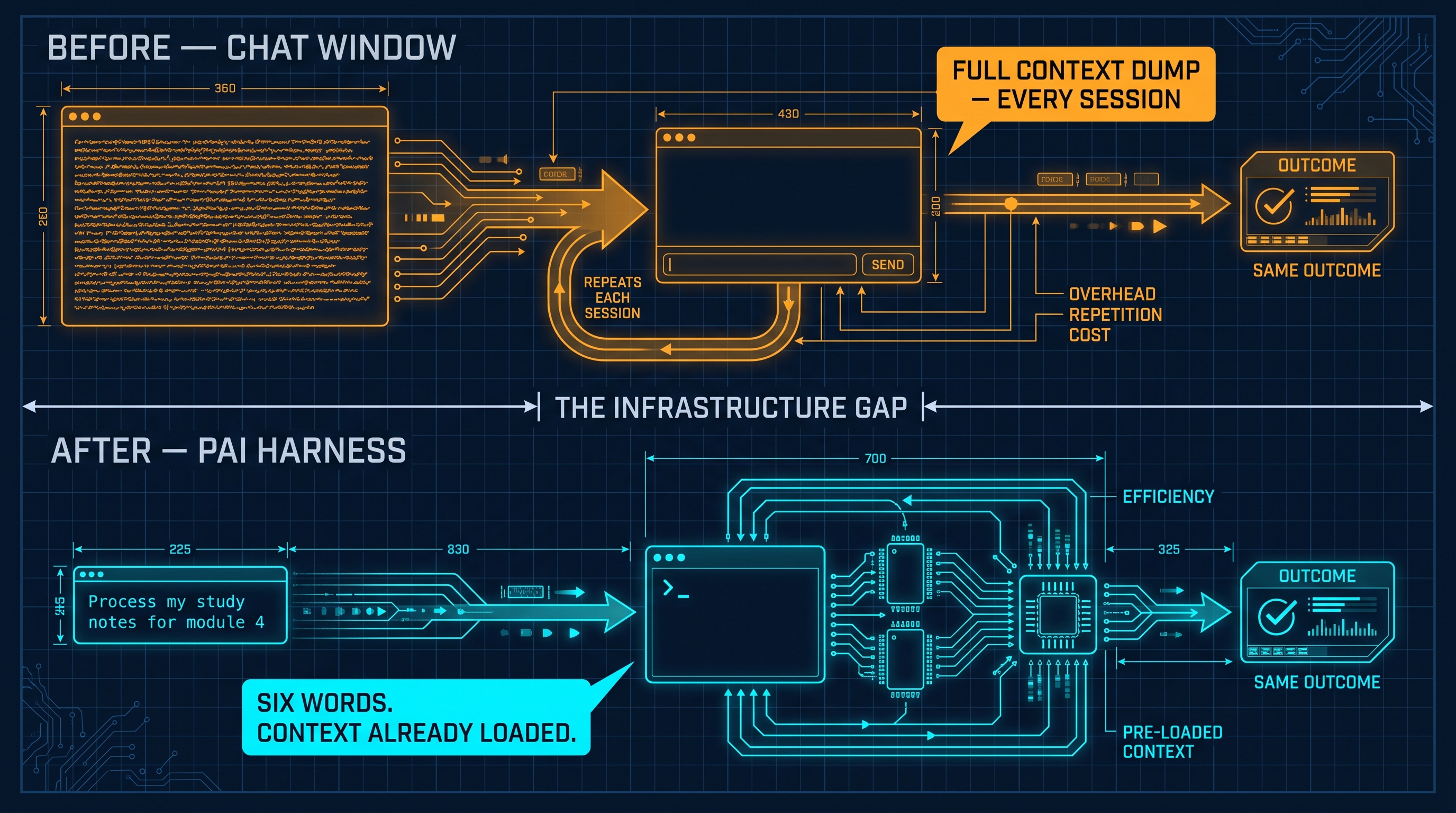
Before and After: The Same Problem, Two Environments
Chat window, eight months ago:
“I have study notes from a certification I’m working through, exported as a Word document from my tablet. I organize my notes in Obsidian under a folder structure by certification and module number. I need you to convert the content to clean markdown, extract the key concepts as a structured summary, generate quiz questions with answers, and format everything to match my existing note structure. The certification is [name], this is module [N], and here’s an example of how my other notes look: [paste example]…”
Then the session ended. Next time I had notes to process — same context dump, from scratch.
With PAI, today:
“Process my study notes for module 4.”
PAI already knows the certification, the Obsidian directory structure, the naming conventions, the quiz format, and which knowledge base to cross-reference. Processing starts immediately. The notes land in the right place in the right format.
The eight-month gap between those two experiences is not better prompting. It is infrastructure.
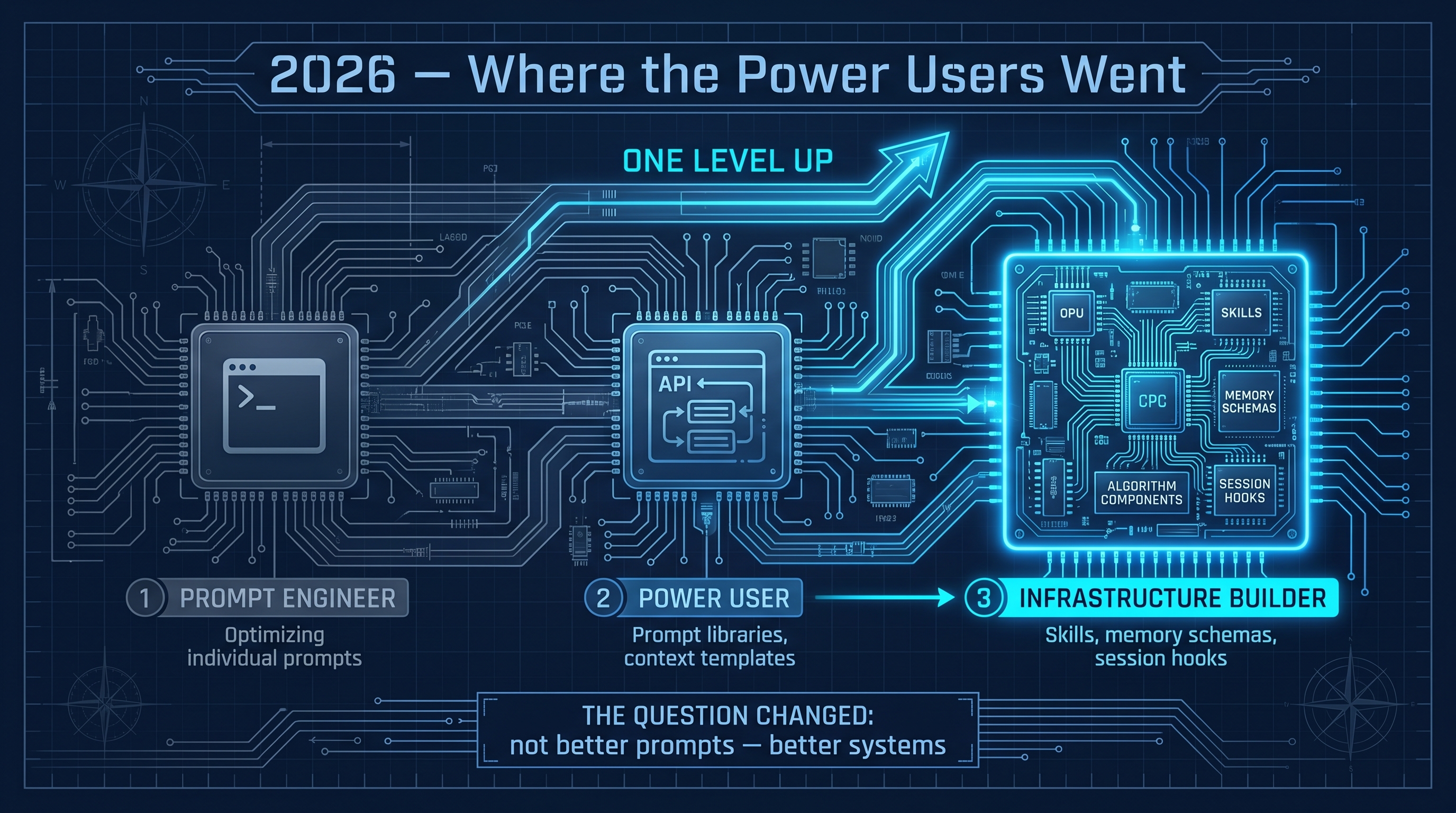
2026: Where the Power Users Went
The practitioners who were deep into prompt engineering two years ago have largely moved on — not to better prompts, but to better systems. They are building skills, writing memory schemas, wiring session hooks, running structured execution algorithms on complex work. The prompt engineer persona is being quietly replaced by the AI infrastructure builder.
This is not about being technical. It is about thinking one level up. Instead of asking how to get a better response to this prompt, you ask what a system would need to know to handle this reliably, every time.
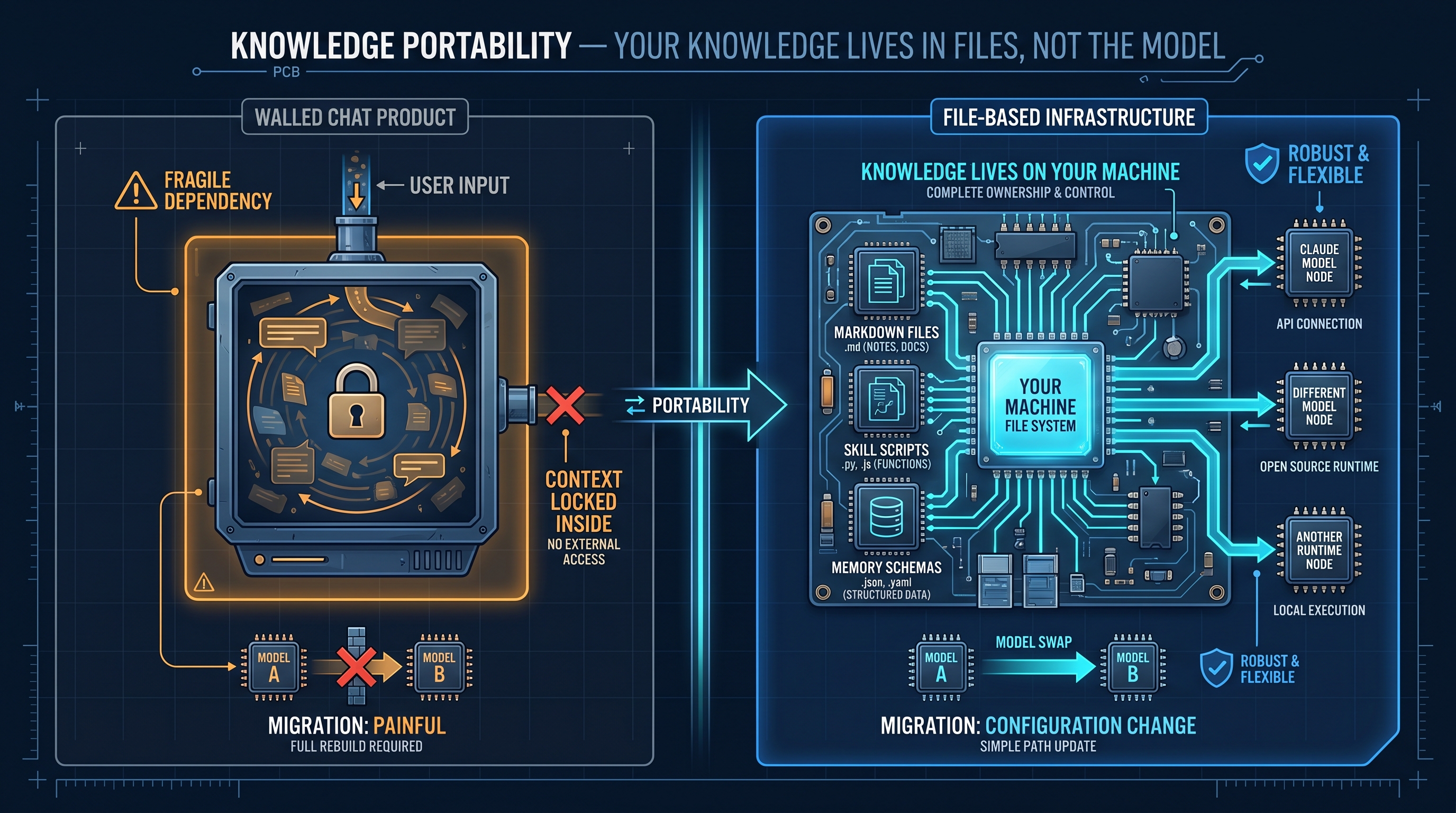
Your Knowledge Doesn’t Live in the Model
One of the less obvious benefits of building infrastructure rather than relying on chat conversations: your knowledge is not locked to any LLM.
When everything lives in a chat window, switching models means starting over. Your context, your conversation history, your accumulated session knowledge — gone. The model you were using knew who you were because you kept telling it. A different model knows nothing.
With PAI, the knowledge lives in files you own. The memory is markdown on your machine. The skills are scripts in a directory. The algorithm is a structured process your runtime executes. None of it is stored inside Claude, or any other model. The AI is the engine, not the warehouse.
That distinction matters more than it sounds. LLMs are evolving fast. A model that is the best choice today may not be the best choice in six months. If your entire working context is entangled with one provider’s chat history, migration is painful. If your context lives in a portable, file-based system, switching the underlying model is a configuration change — not a rebuild.
I run PAI on Claude today because it is the best fit for how I work right now. But the memory schema, the skill library, the algorithm — all of it would transfer to a different model without losing a session’s worth of context. That portability is a deliberate design choice, and it is one of the most underappreciated properties of building on open infrastructure rather than inside a walled chat product.
Credit Where It’s Due
PAI did not emerge from a vacuum. A significant part of the thinking behind it — the idea that AI should be augmenting structured, intentional human systems rather than replacing ad-hoc conversations — traces directly to the work of Daniel Miessler .
Daniel has been articulating the case for AI infrastructure thinking longer than most. His Fabric project, his writing on augmented intelligence, and his broader framing of what it means to build systems that extend human capability rather than just answer questions — all of it shaped how PAI was conceived and how it continues to evolve.
The shift from “better prompts” to “better systems” is not a new idea. It just needed enough tooling to become practical. Daniel saw that early.
Where to Start
PAI is open-source. Claude Code is free to start — it is Anthropic’s official CLI, available to any Claude user. The distance between using AI in a chat window and running it inside a harness is smaller than it looks, and the compounding return starts from the first session where PAI remembers something you did not have to re-enter.
If you are still re-explaining yourself every time you open a new tab, that is the problem worth solving.