If a Script Can Do It, Don’t Ask the LLM
If a Script Can Do It, Don’t Ask the LLM
When your AI system is spending inference tokens to parse date fields, strip PDF formatting artifacts, or convert file syntax — that is not an AI problem. That is an architecture problem. Code can handle all of those tasks deterministically, faster, cheaper, and more accurately than any language model. If your token bill is high and your outputs are inconsistent, the problem is usually not the model. It is what you are handing the model.
PAI treats every token as a resource allocation decision. If a script can do it, a script does it. The model gets the part that actually requires reasoning.
The Structural Tax
Most AI workflows are built around convenience. You have a PDF — you upload it. You have a session log — you paste it in. You have a directory of files — you point the model at the folder. The model figures it out.
That approach works well enough for one-off tasks. It breaks down at scale, in recurring workflows, and anywhere precision matters.
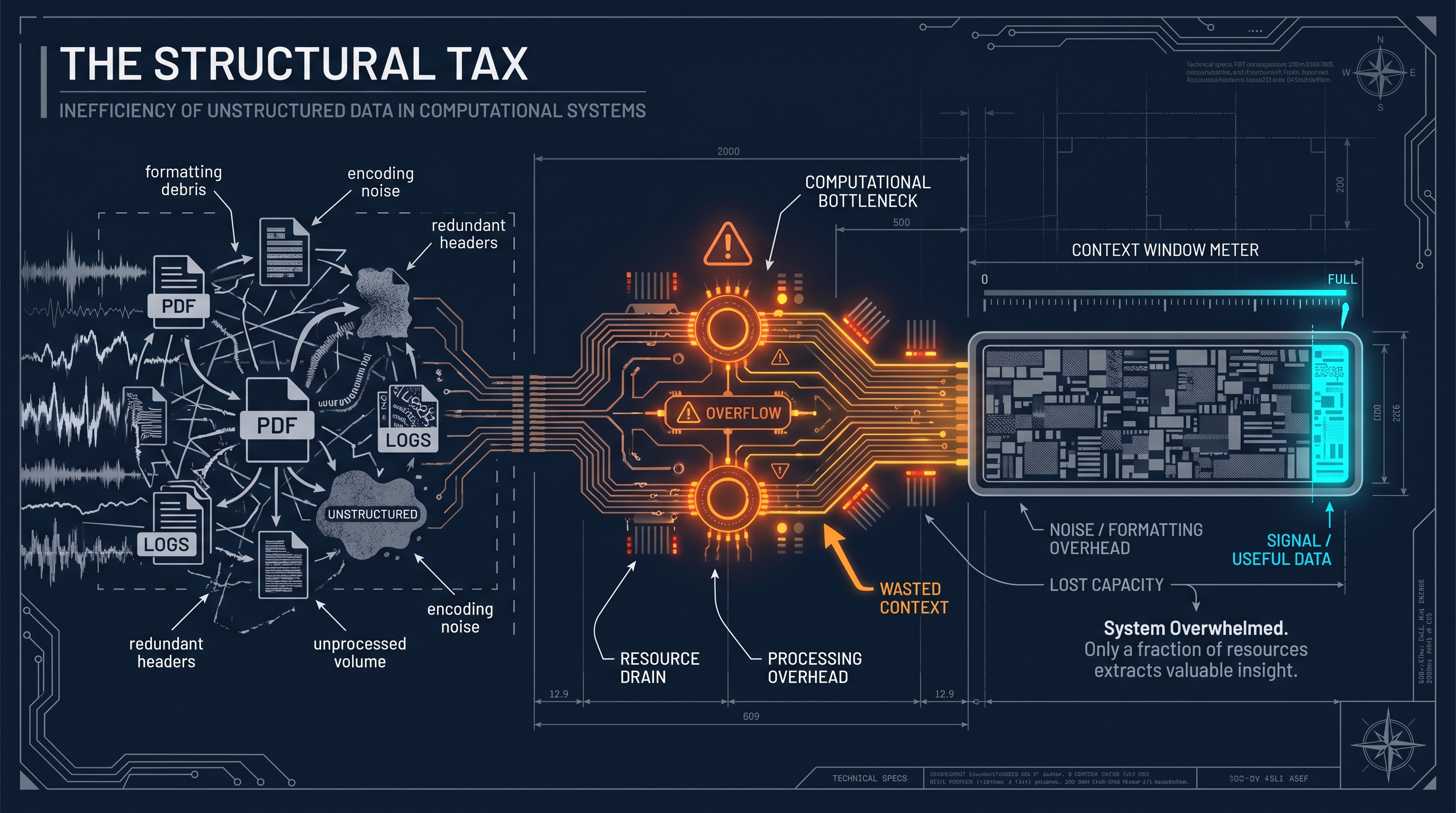
Raw PDFs carry structural overhead that has nothing to do with the content you care about: page headers, footers, column artifacts, encoding noise, redundant whitespace, and metadata that made sense in the original layout but becomes garbage in a text stream. A language model consuming that document is spending a meaningful portion of its context window on formatting debris. That cost compounds across every document in every workflow.
The same pattern shows up everywhere. Raw session transcripts contain tool call metadata, timestamps, and infrastructure details that are irrelevant to extracting what was learned. Full database contents are too large to fit in context, so the model guesses at relevance instead of reasoning over curated results. Obsidian-flavored Markdown with custom image syntax breaks rendering in any system that was not built for it.
Every one of these is a structural problem. None of them require intelligence to solve. They require code.
What PAI Does Instead
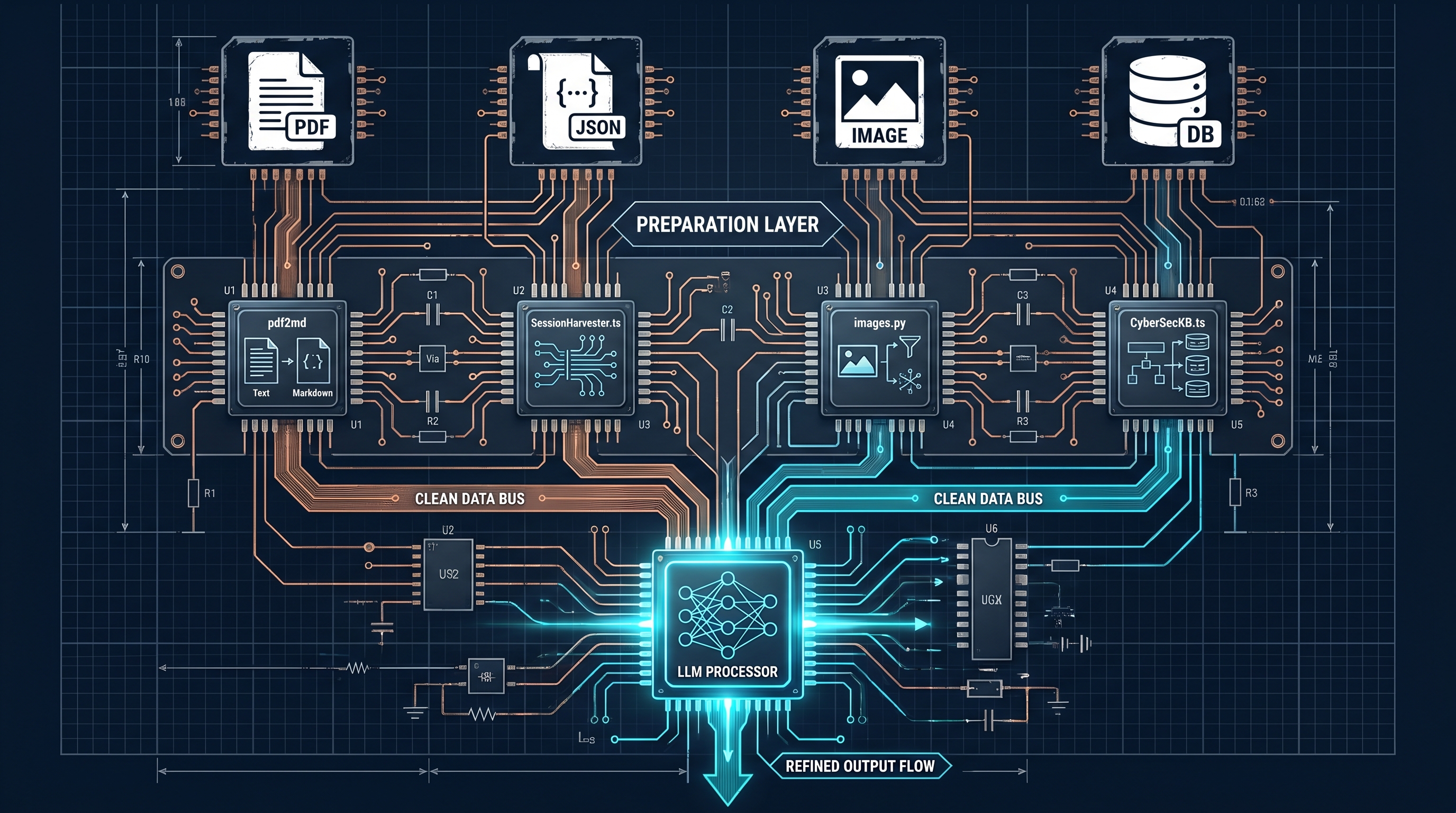
PAI operates on a two-phase model: scripts handle structure, the LLM handles reasoning. The handoff only happens after the mechanical work is done.
A few examples of how this plays out in practice.
PDF to Markdown conversion. When I ingest Oracle HCM documentation — dense, multi-column PDFs that can run hundreds of pages — nothing goes to the LLM in PDF form. A Python script converts the document to clean Markdown first, stripping formatting artifacts and preserving the content hierarchy. The model sees structured text, not a scanned layout. The difference in token consumption is substantial, and the difference in output quality is larger still.
Session harvesting. Claude Code sessions produce raw JSON transcripts containing every tool call, every response, and a lot of infrastructure noise. SessionHarvester.ts parses those transcripts before any analysis happens. It extracts structured learning signals — what worked, what failed, what decisions were made — and writes them to a clean format. The LLM receives a curated summary, not a raw dump.
Activity parsing. ActivityParser.ts does the same for daily activity logs: reads session files, extracts structured change records, and produces a clean representation of what changed in the PAI system. No model inference required until there is something worth reasoning about.
Knowledge base search. The cybersecurity knowledge base holds over fifty books worth of content in a local PostgreSQL vector store. When a query comes in, CyberSecKB.ts runs a similarity search and returns the most relevant passages. The LLM reasons over that curated result set — not the entire library. Retrieval is deterministic. Reasoning is probabilistic. They are separate steps by design.
Image pipeline. Obsidian uses  syntax for embedded images. Hugo uses standard Markdown. images.py handles the conversion and copies files to the correct static directory at publish time. No LLM is involved at any point in that pipeline. It is a string transformation and a file copy — exactly the kind of task code should own.
The Boundary Is the Design
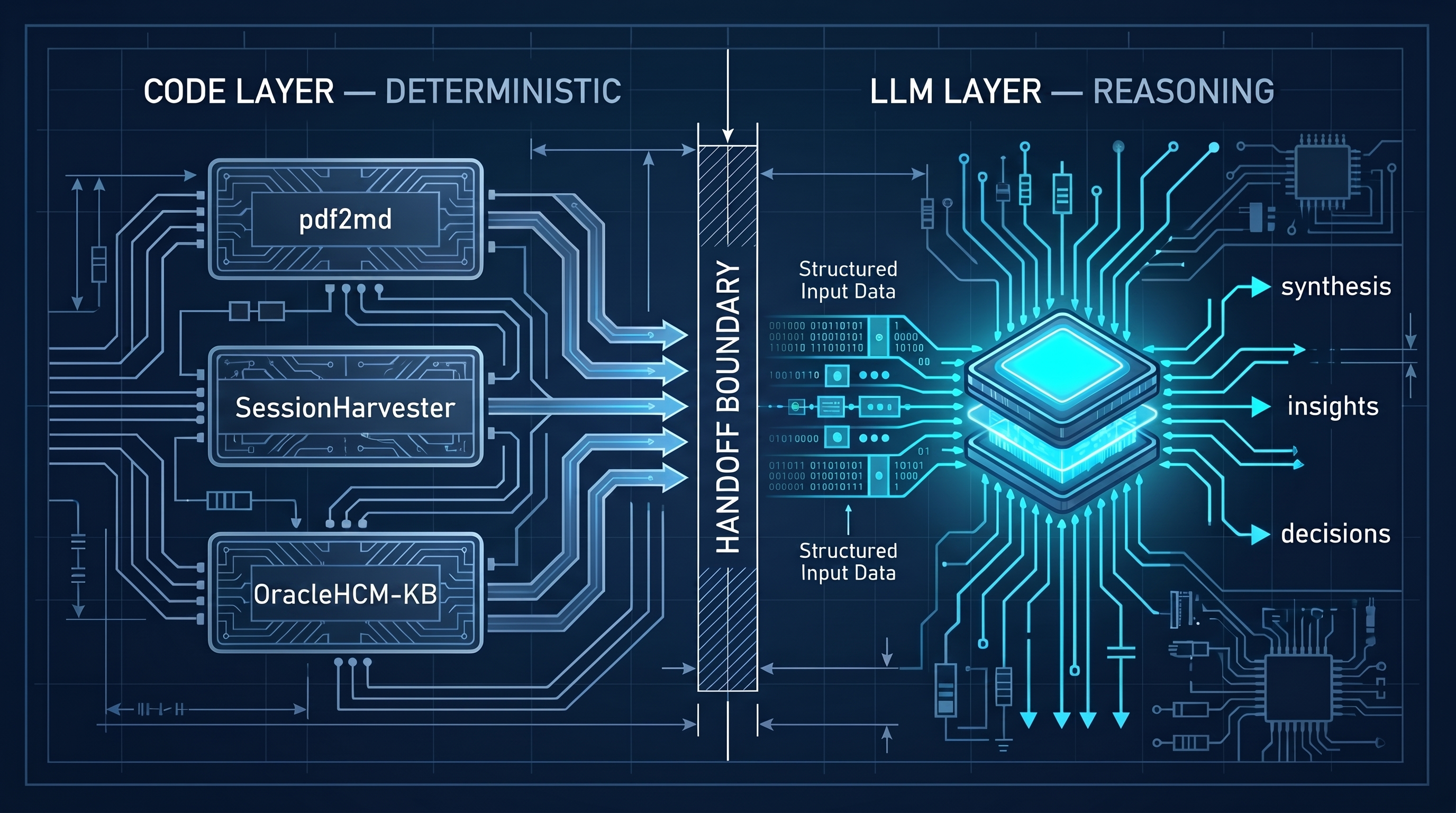
The two-phase pattern is not a workaround. It is the architecture.
Every AI workflow has a boundary between deterministic computation and probabilistic reasoning. The question is where you draw it. Drawing it too early means the model is doing structural work it is not suited for: burning tokens on format conversion, wasting context on irrelevant metadata, producing inconsistent output because the input was inconsistent. Drawing it correctly means the model receives exactly what it needs to do the work only it can do.
This is a different problem than the one prompt engineering was designed to solve. Prompt engineering is about communicating intent clearly to a model. The code-first pattern is about not asking the model to earn the right to see your data by first organizing it. That work should already be done.
The scripts in PAI are not wrappers around LLM calls. They are the preparation layer — the part of the system that exists specifically so the model does not have to deal with structure. Once that layer is in place, the model’s job gets narrower and cleaner. It reasons. It synthesizes. It makes judgment calls. It does not convert file formats.
The Result
When the pipeline is built correctly, token consumption goes down and output quality goes up — not because the model improved, but because the input did. The model is working with clean data in a consistent format, scoped to exactly what is relevant. The structural variables are removed before inference begins.
That is the return on building the prep layer. Less waste. More signal. A model that can focus on the part of the problem that actually requires a model.